这是一篇使用 PINN 和 PT 对称解决可积非局部方程逆问题和正问题的论文。
我们先来看看这篇论文的摘要:
英文原文:
Since the P T -symmetric nonlocal equations contain the physical information of the P T -symmetric, it is very appropriate to embed the physical information of the P T -symmetric into the loss function of PINN, named PTS-PINN. For general P T -symmetric nonlocal equations, especially those equations involving the derivation of nonlocal terms, due to the existence of nonlocal terms, directly using the original PINN method to solve such nonlocal equations will face certain challenges. This problem can be solved by the PTS-PINN method which can be illustrated in two aspects. First, we treat the nonlocal term of the equation as a new local component, so that the equation is coupled at this time. In this way, we successfully avoid differentiating nonlocal terms in neural networks. On the other hand, in order to improve the accuracy, we make a second improvement, which is to embed the physical information of the P T -symmetric into the loss function. Through a series of independent numerical experiments, we evaluate the efficacy of PTS-PINN in tackling the forward and inverse problems for the nonlocal nonlinear Schr ̈odinger (NLS) equation, the nonlocal derivative NLS equation, the nonlocal (2+1)-dimensional NLS equation, and the nonlocal three wave interaction systems. The numerical experiments demonstrate that PTS-PINN has good performance. In particular, PTS-PINN has also demonstrated an extraordinary ability to learn large space-time scale rogue waves for nonlocal equations.
翻译:
由于 PT -对称非局部方程包含 PT -对称的物理信息,因此将 PT -对称的物理信息嵌入 PINN 的损耗函数 PTS-PINN 中非常合适。对于一般的 PT -对称非局部方程,尤其是涉及非局部项推导的方程,由于非局部项的存在,直接使用原始 PINN 方法求解此类非局部方程会面临一定挑战。这个问题可以通过 PTS-PINN 方法解决,方法可以通过两个方面说明。首先,我们将方程的非局部项视为新的局部分量,因此此时方程是耦合的。通过这种方式,我们成功地避免了在神经网络中区分非局部项。另一方面,为了提高准确性,我们做了第二项改进,即将 P、T 对称的物理信息嵌入到损失函数中。通过一系列独立数值实验,我们评估了 PTS-PINN 在解决非局部非线性施尔·奥丁格(NLS)、非局部导数 NLS 方程、非局部(2+1)维 NLS 方程以及非局部三波相互作用系统的前向和逆问题方面的效能。数值实验表明 PTS-PINN 表现良好。特别是,PTS-PINN 还展现出了学习非局部方程中大规模时空尺度流氓波的非凡能力。
第一个可积非局部方程是由 Ablowitz 等人[5]提出的非局部非线性 Schrodinger(NLS)方程,记为
i q t ( x , t ) + q x x ( x , t ) + 1 2 q 2 ( x , t ) q ∗ ( − x , t ) = 0 , (1.1) iq_t(x,t)+q_{xx}(x,t)+\frac{1}{2}q^2(x,t)q^*(-x,t)=0,\tag{1.1} i q t ( x , t ) + q xx ( x , t ) + 2 1 q 2 ( x , t ) q ∗ ( − x , t ) = 0 , ( 1.1 ) 其中,星号 ∗ ∗ ∗ q ∗ ( − x , t ) q^∗(−x, t) q ∗ ( − x , t ) ( 1.1 ) (1.1) ( 1.1 ) V ( x , t ) = q ( x , t ) q ∗ ( − x , t ) V(x,t) = q(x,t)q^∗(−x,t) V ( x , t ) = q ( x , t ) q ∗ ( − x , t ) x → − x x \to −x x → − x q ( x , t ) q(x,t) q ( x , t ) q ∗ ( − x , t ) q^∗(−x,t) q ∗ ( − x , t )
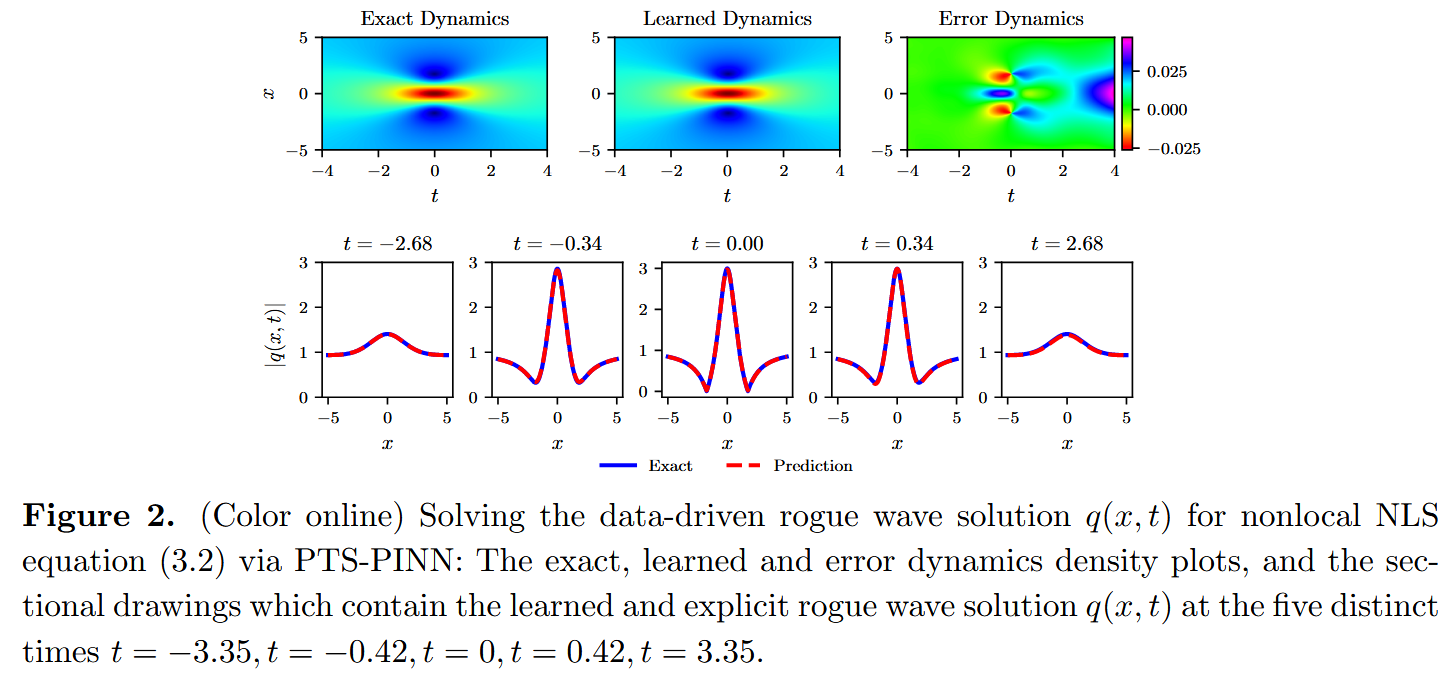
流氓波,也称为杀手波,近年来在海洋环境和光纤领域引起了广泛关注[15, 16]。此外,流氓波的理论预测和实验观测也被记录下来[17, 18]。Peregrine 提出的 NLS 一阶有理解在解释流氓波现象方面起到了关键作用[19]。随后,分析流氓波解已为许多可积系统推导出,如 AB 系统[20]、三波相互作用方程[21]、Kundu-Eckhaus(KE)方程[22]等。之前大多数导出的流氓波都涉及局部可积方程。相比之下,非局部可积方程中的流氓波是一个有趣且新颖的研究领域,已被生成用于多种非局部可积方程,包括非局部 P T -对称 NLS 方程[23]、非局部导数 NLS 方程[24]、非局部 Davey-Stewartson(DS)系统[25,26]等。
本文通过使用 PINN 深度学习方法,研究数据驱动解,特别是流氓波解,应用于多个可积非定域方程。作为典型的具体例子,我们关注非局部 NLS 方程 ( 1.1 ) (1.1) ( 1.1 )
i q t ( x , t ) − q x x ( x , t ) − ( q 2 ( x , t ) q ∗ ( − x , t ) ) x = 0 , (1.2) iq_t(x,t)-q_{xx}(x,t)-(q^2(x,t)q^*(-x,t))_x=0,\tag{1.2} i q t ( x , t ) − q xx ( x , t ) − ( q 2 ( x , t ) q ∗ ( − x , t ) ) x = 0 , ( 1.2 ) 非局部(2+1)维 NLS 方程[28,29]
i q t + q x y + q r = 0 , r y = [ q ( x , y , t ) q ( − x , − y , t ) ∗ ] x , (1.3) \begin{aligned}
iq_t+q_{xy}+qr=0,\\ \tag{1.3}
r_y=[q(x,y,t)q(-x,-y,t)^*]_x,\\
\end{aligned} i q t + q x y + q r = 0 , r y = [ q ( x , y , t ) q ( − x , − y , t ) ∗ ] x , ( 1.3 ) 以及非局部三波相互作用系统[30]
q 1 t + a q 1 x − q 2 ( − x , − t ) q 3 ( − x , − t ) = 0 , q 2 t + b q 2 x − q 1 ( − x , − t ) q 3 ( − x , − t ) = 0 , q 3 t + c q 3 x + q 1 ( − x , − t ) q 2 ( − x , − t ) = 0. (1.4) \begin{aligned}
q_{1t}+aq_{1x}-q_2(-x,-t)q_3(-x,-t)&=0,\\
q_{2t}+bq_{2x}-q_1(-x,-t)q_3(-x,-t)&=0,\\ \tag{1.4}
q_{3t}+cq_{3x}+q_1(-x,-t)q_2(-x,-t)&=0.\\
\end{aligned} q 1 t + a q 1 x − q 2 ( − x , − t ) q 3 ( − x , − t ) q 2 t + b q 2 x − q 1 ( − x , − t ) q 3 ( − x , − t ) q 3 t + c q 3 x + q 1 ( − x , − t ) q 2 ( − x , − t ) = 0 , = 0 , = 0. ( 1.4 ) 对于非局部导数 NLS 方程,孤子解此前已通过 IST[31]提出。此外,利用 DT 对其周期波解和双周期背景下的流氓波进行了研究[24,27]。在非局部(2+1)维 NLS 方程的背景下,高阶有理解和相互作用解通过广义 DT 得出[32]。此外,利用长波极限法,还探索了非局部(2+1)维 NLS 方程中流氓波�和半有理解的分析[28,29]。对于非局部三波相互作用系统,a、b、c 是常数参数。三波相互作用方程的反散射变换被详细研究,并推导出其孤子解[30]。
在计算机计算能力日益增长的背景下,深度学习已成为解决偏微分方程(PDE)的高效技术工具。值得注意的是,Raissi 等人借助一般近似定理[33]和自动微分技术[34],提出了基于物理约束的深度学习框架,用于高效求解偏微分方程,称为物理信息神经网络(PINN)[4]。PINN 的基本思想是将偏微分方程嵌入神经网络的损失函数中,从而通过相对于损失函数的梯度下降实现偏微分方程的数值求解,同时结合初始条件和边界条件。与传统数值方法相比,PINN 展示了在有限数据下求解偏微分方程的能力,同时便于方程参数的发现。随后,PINN 在多个领域引起了广泛关注。在可积系统领域,陈教授团队率先利用 PINN 方法构建数据驱动的孤子解、呼吸波、流氓波和流氓周期波,适用于多种非线性演化方程,包括 KdV 方程、导数 NLS 方程、陈利刘方程和变量系数模型等[35–40]。与此同时,其他学者也提出了数据驱动方程的显著成果,如 Gross-Pitaevskii 方程、Boussinesq 方程、NLS 方程、耦合 NLS 方程、Benjamin-Ono 方程、具有 PT -对称势的饱和 NLS 方程等[41–52]。尽管迄今取得显著成功,PINN 在解决需要更高精度和效率的更复杂问题时仍面临挑战。因此,开发了增强版 PINN 的方案。值得注意的改进包括将残余偏微分方程的梯度信息嵌入损失函数,从而引入了梯度增强的 PINN[53]。此外,林和陈通过将守恒量纳入均方误差损失,引入了两阶段 PINN[54]。引入了自适应激活函数[55]和自适应损耗平衡 PINN[56]等技术,以加快网络训练并提高准确性。对称增强物理信息神经网络的发展通过将李氏对称性或偏微分方程的非经典对称性纳入损失函数,进一步提升了准确性[57]。
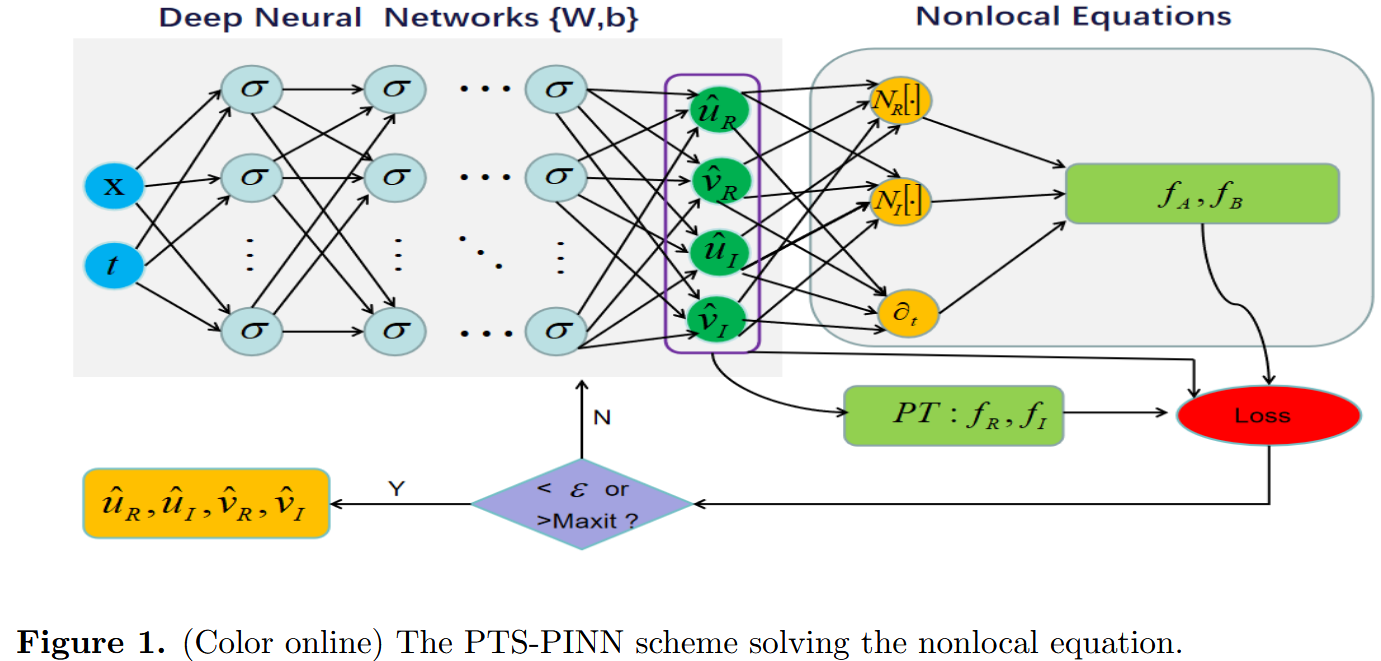
非局部可积方程区别于局部方程,其具有独特的空间和/或时间耦合,带来新的物理效应并激发创新应用。值得注意的是,非局部可积方程具有 PT -对称性质,可以嵌入损耗函数中以提高 PINN 算法求解非定域可积方程的精度。因此,应用 PINN 对于研究此类非局部可积方程变得至关重要。然而,由于存在非局部项,直接采用原始 PINN 方法处理此类非局部方程存在特殊挑战。本文介绍了 PTS-PINN 来求解一般的 PT -对称非局部方程,特别是具有非局部项导数的非局部方程。PTS-PINN 的基本概念涵盖两个关键方面。首先,我们将方程的非局部项视为一个新的局部分量,从而导致方程的耦合。这种方法实际上消除了在神经网络中区分非局部项的需求。其次,为了提高准确性,我们将 PT -对称性物理信息纳入损失函数,实现了第二个改进。
本文大纲组织如下:第二部分简要介绍 PTS-PINN 的主要思想。在第三部分,我们给出了非局部 NLS 方程、非局部导数 NLS 方程和非局部(2+1)维 NLS 方程的多组独立实验,以展示 PTS-PINN 的有效性。数据驱动的流氓波解、周期波解、呼吸波解通过 PTS-PINN 方案进行研究。此外,应用 PTS-PINN 方法,第 4 节讨论了非局部(2+1)维 NLS 方程和非局部三波相互作用系统的数据驱动参数发现。结论见最后一节。
PT -对称性 PINN 的主要思想
本节简要介绍了 PT -对称性 PINN 在处理非局部复偏微分方程中的应用。考虑一个一般的非局部复偏微分方程,其形式如下:
{ i q ( x , t ) t + N [ q ( x , t ) , q ( − x , t ) ] = 0 , x ∈ Ω , t ∈ [ T 0 , T 1 ] , q ( x , T 0 ) = h 0 ( x ) , x ∈ Ω , q ( x , t ) = h Γ ( x , t ) , x ∈ ∂ Ω , t ∈ [ T 0 , T 1 ] , (2.1) \left\{ \begin{array}{l}
iq(\mathbf{x},t)_t+\mathcal{N} [q(\mathbf{x},t),q(-\mathbf{x},t)]=0,\quad \mathbf{x}\in \Omega ,\quad t\in [T_0,T_1],\\
q(\mathbf{x},T_0)=h_0(\mathbf{x}),\quad \mathbf{x}\in \Omega ,\\ \tag{2.1}
q(\mathbf{x},t)=h_{\Gamma}(\mathbf{x},t),\quad \mathbf{x}\in \partial \Omega ,\quad t\in [T_0,T_1],\\
\end{array} \right. ⎩ ⎨ ⎧ i q ( x , t ) t + N [ q ( x , t ) , q ( − x , t )] = 0 , x ∈ Ω , t ∈ [ T 0 , T 1 ] , q ( x , T 0 ) = h 0 ( x ) , x ∈ Ω , q ( x , t ) = h Γ ( x , t ) , x ∈ ∂ Ω , t ∈ [ T 0 , T 1 ] , ( 2.1 ) 其中,变量 x \mathbf{x} x N N N x = ( x 1 , x 2 , … , x N ) \mathbf{x} = (x_1,x_2, \dots ,x_N) x = ( x 1 , x 2 , … , x N ) x \mathbf{x} x Ω \Omega Ω t t t [ T 0 , T 1 ] [T_0,T_1] [ T 0 , T 1 ] N [ ⋅ ] N[·] N [ ⋅ ] q ( x , t ) q(\mathbf{x},t) q ( x , t ) q ( − x , t ) q(−\mathbf{x},t) q ( − x , t ) x \mathbf{x} x r r r Ω \Omega Ω ∂ Ω \partial \Omega ∂ Ω ( 2.1 ) (2.1) ( 2.1 ) q = q ( x , t ) q = q(\mathbf{x},t) q = q ( x , t ) ( 2.1 ) (2.1) ( 2.1 ) q ( x , t ) q(\mathbf{x},t) q ( x , t ) u R ( x , t ) + i u I ( x , t ) u_R(\mathbf{x},t)+ iu_I(\mathbf{x},t) u R ( x , t ) + i u I ( x , t ) u R u_R u R u I u_I u I
一个广泛认可的事实是,具有 PT -对称性的非局部方程由 PT 势能 V ( x , t ) = q ( x , t ) q ∗ ( − x , t ) V(\mathbf{x},t) = q(\mathbf{x},t)q^∗(−\mathbf{x},t) V ( x , t ) = q ( x , t ) q ∗ ( − x , t ) V ( x , t ) V(\mathbf{x},t) V ( x , t ) V R ( x , t ) V_R(\mathbf{x},t) V R ( x , t ) V ( x , t ) V(\mathbf{x},t) V ( x , t ) V I ( x , t ) V_I(\mathbf{x},t) V I ( x , t ) V R ( x , t ) = V R ( − x , t ) V_R(\mathbf{x},t) = V_R(−\mathbf{x},t) V R ( x , t ) = V R ( − x , t ) V I ( x , t ) = − V I ( − x , t ) V_I(\mathbf{x},t)= −V_I(−\mathbf{x},t) V I ( x , t ) = − V I ( − x , t ) q ( − x , t ) = v R ( x , t ) + i v I ( x , t ) q(−\mathbf{x},t) = v_R(\mathbf{x},t) + iv_I (\mathbf{x},t) q ( − x , t ) = v R ( x , t ) + i v I ( x , t )
u_R(\mathbf{x},t)=v_R(-\mathbf{x},t),\qquad u_I(\mathbf{x},t)=v_I(-\mathbf{x},t).\tag{2.2}
将 q ( x , t ) = u R ( x , t ) + i u I ( x , t ) q(\mathbf{x},t) = u_R(\mathbf{x},t) + iu_I(\mathbf{x},t) q ( x , t ) = u R ( x , t ) + i u I ( x , t ) q ( − x , t ) = v R ( x , t ) + i v I ( x , t ) q(−\mathbf{x}, t) = v_R(\mathbf{x},t) + iv_I(\mathbf{x},t) q ( − x , t ) = v R ( x , t ) + i v I ( x , t ) ( 2.1 ) (2.1) ( 2.1 )
{ ( u R ) t + N R [ u R , u I , v R , v I ] = 0 , ( u I ) t + N I [ u R , u I , v R , v I ] = 0. (2.3) \left\{ \begin{array}{l}
(u_R)_t+\mathcal{N} _R[u_R,u_I,v_R,v_I]=0,\\ \tag{2.3}
(u_I)_t+\mathcal{N} _I[u_R,u_I,v_R,v_I]=0.\\
\end{array} \right. { ( u R ) t + N R [ u R , u I , v R , v I ] = 0 , ( u I ) t + N I [ u R , u I , v R , v I ] = 0. ( 2.3 ) 在 PINN 的开创性工作基础上,我们定义了解 ( u R ( x , t ) , u I ( x , t ) , v R ( x , t ) , v I ( x , t ) ) (u_R(\mathbf{x}, t), u_I(\mathbf{x}, t), v_R(\mathbf{x}, t), v_I (\mathbf{x}, t)) ( u R ( x , t ) , u I ( x , t ) , v R ( x , t ) , v I ( x , t )) ( u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ ) ) (\hat{u}_R(\mathbf{x}, t; θ), \hat{u}_I (\mathbf{x}, t; θ), \hat{v}_R(\mathbf{x}, t; θ), \hat{v}_I (\mathbf{x}, t; θ)) ( u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ )) θ θ θ M M M ( M − 1 ) (M−1) ( M − 1 ) m m m ( m = 1 , 2 , … , M − 1 ) (m = 1, 2,\dots, M-1) ( m = 1 , 2 , … , M − 1 ) N m N_m N m N m N_m N m ( m + 1 ) (m + 1) ( m + 1 ) T m \mathcal{T}_m T m σ ( ⋅ ) \sigma(·) σ ( ⋅ )
X [ m ] = T m ( X [ m − 1 ] ) = σ ( W [ m ] X [ m − 1 ] + b [ m ] ) , (2.4) {\mathbf{X}}^{[m]}=\mathcal{T} _m(\mathbf{X}^{[m-1]})=\sigma ({W}^{[m]}\mathbf{X}^{[m-1]}+{b}^{[m]}),\tag{2.4} X [ m ] = T m ( X [ m − 1 ] ) = σ ( W [ m ] X [ m − 1 ] + b [ m ] ) , ( 2.4 ) 其中,X [ m ] \mathbf{X}^{[m]} X [ m ] m m m X [ 0 ] \mathbf{X}^{[0]} X [ 0 ] ( x 1 , x 2 , … , x N , t ) (x_1,x_2,\dots,x_N,t) ( x 1 , x 2 , … , x N , t ) m m m W [ m ] ∈ R N m × N m − 1 \mathbf{W}^{[m]}\in \mathbb{R}^{N_m×N_{m−1}} W [ m ] ∈ R N m × N m − 1 b [ m ] ∈ R N m b^{[m]} \in \mathbb{R}^{N_m} b [ m ] ∈ R N m θ = W [ m ] , b [ m ] 1 ≤ m ≤ M θ = {W[m],b[m]}_{1 \le m \le M} θ = W [ m ] , b [ m ] 1 ≤ m ≤ M u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ ) \hat{u}_R(\mathbf{x},t;θ),\hat{u}_I(\mathbf{x},t;θ),\hat{v}_R(\mathbf{x},t;θ),\hat{v}_I(\mathbf{x},t;θ) u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ )
{ f A ( x , t ; θ ) : = ∂ ∂ t u ^ R ( x , t ; θ ) + N R [ u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ ) ] , f B ( x , t ; θ ) : = ∂ ∂ t u ^ I ( x , t ; θ ) + N I [ u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ ) ] . (2.5) \left\{ \begin{array}{l}
f_A(\mathbf{x},t;\theta ):=\frac{\partial}{\partial t}\hat{u}_R(\mathbf{x},t;\theta )+\mathcal{N} _R[\hat{u}_R(\mathbf{x},t;\theta ),\hat{u}_I(\mathbf{x},t;\theta ),\hat{v}_R(\mathbf{x},t;\theta ),\hat{v}_I(\mathbf{x},t;\theta )],\\
f_B(\mathbf{x},t;\theta ):=\frac{\partial}{\partial t}\hat{u}_I(\mathbf{x},t;\theta )+\mathcal{N} _I[\hat{u}_R(\mathbf{x},t;\theta ),\hat{u}_I(\mathbf{x},t;\theta ),\hat{v}_R(\mathbf{x},t;\theta ),\hat{v}_I(\mathbf{x},t;\theta )].\\ \tag{2.5}
\end{array} \right. { f A ( x , t ; θ ) := ∂ t ∂ u ^ R ( x , t ; θ ) + N R [ u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ )] , f B ( x , t ; θ ) := ∂ t ∂ u ^ I ( x , t ; θ ) + N I [ u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ )] . ( 2.5 ) 利用对 u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ ) \hat{u}_R(\mathbf{x},t;θ),\hat{u}_I(\mathbf{x},t;θ),\hat{v}_R(\mathbf{x},t;θ),\hat{v}_I(\mathbf{x},t;θ) u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ ) f A ( x , t ; θ ) , f B ( x , t ; θ ) f_A(x,t;θ),f_B(x,t;θ) f A ( x , t ; θ ) , f B ( x , t ; θ )
{ f R ( x , t ; θ ) : = u ^ R ( x , t ; θ ) − v ^ R ( − x , t ; θ ) , f I ( x , t ; θ ) : = u ^ I ( x , t ; θ ) − v ^ I ( − x , t ; θ ) . (2.6) \left\{ \begin{array}{l}
f_R(\mathbf{x},t;\theta ):=\hat{u}_R(\mathbf{x},t;\theta )-\hat{v}_R(-\mathbf{x},t;\theta ),\\
f_I(\mathbf{x},t;\theta ):=\hat{u}_I(\mathbf{x},t;\theta )-\hat{v}_I(-\mathbf{x},t;\theta ).\\
\end{array} \right. \tag{2.6} { f R ( x , t ; θ ) := u ^ R ( x , t ; θ ) − v ^ R ( − x , t ; θ ) , f I ( x , t ; θ ) := u ^ I ( x , t ; θ ) − v ^ I ( − x , t ; θ ) . ( 2.6 ) 随后,采用多隐藏层深度神经网络训练与潜在函数 u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ ) \hat{u}_R(\mathbf{x},t;θ),\hat{u}_I(\mathbf{x},t;θ),\hat{v}_R(\mathbf{x},t;θ),\hat{v}_I(\mathbf{x},t;θ) u ^ R ( x , t ; θ ) , u ^ I ( x , t ; θ ) , v ^ R ( x , t ; θ ) , v ^ I ( x , t ; θ ) f A , f B , f R , f I f_A,f_B,f_R,f_I f A , f B , f R , f I
L o s s θ = L o s s u ^ R + L o s s u ^ I + L o s s v ^ R + L o s s v ^ I + L o s s f A + L o s s f B + L o s s f R + L o s s f I , (2.7) \begin{aligned}
Loss_{\theta}=Loss_{\hat{u}_R}+Loss_{\hat{u}_I}+Loss_{\hat{v}_R}+Loss_{\hat{v}_I}\\
+Loss_{f_A}+Loss_{f_B}+Loss_{f_R}+Loss_{f_I},\\ \tag{2.7}
\end{aligned} L os s θ = L os s u ^ R + L os s u ^ I + L os s v ^ R + L os s v ^ I + L os s f A + L os s f B + L os s f R + L os s f I , ( 2.7 ) 以及
{ Loss u ^ R = 1 N I B ∑ i = 1 N I B ∣ u ^ R ( x I B i , t I B i ; θ ) − u R i ∣ 2 , Loss u ^ I = 1 N I B ∑ i = 1 N I B ∣ u ^ I ( x I B i , t I B i ; θ ) − u I i ∣ 2 , Loss v ^ R = 1 N I B ∑ i = 1 N I B ∣ v ^ R ( x I B i , t I B i ; θ ) − v R i ∣ 2 , Loss v ^ I = 1 N I B ∑ i = 1 N I B ∣ v ^ I ( x I B i , t I B i ; θ ) − v I i ∣ 2 , Loss f A = 1 N f ∑ j = 1 N f ∣ f u ^ ( x f j , t f j ) ∣ 2 , Loss f B = 1 N f ∑ j = 1 N f ∣ f v ^ ( x f j , t f j ) ∣ 2 , Loss f R = 1 N f ∑ j = 1 N f ∣ f R ( x f j , t f j ) ∣ 2 , Loss f I = 1 N f ∑ j = 1 N f ∣ f I ( x f j , t f j ) ∣ 2 , (2.8) \left\{\begin{array}{l}
\operatorname{Loss}_{\hat{u}_{R}}=\frac{1}{N_{I B}} \sum_{i=1}^{N_{I B}}\left|\hat{u}_{R}\left(\mathbf{x}_{I B}^{i}, t_{I B}^{i} ; \theta\right)-u_{R}^{i}\right|^{2}, \\
\operatorname{Loss}_{\hat{u}_{I}}=\frac{1}{N_{I B}} \sum_{i=1}^{N_{I B}}\left|\hat{u}_{I}\left(\mathbf{x}_{I B}^{i}, t_{I B}^{i} ; \theta\right)-u_{I}^{i}\right|^{2}, \\
\operatorname{Loss}_{\hat{v}_{R}}=\frac{1}{N_{I B}} \sum_{i=1}^{N_{I B}}\left|\hat{v}_{R}\left(\mathbf{x}_{I B}^{i}, t_{I B}^{i} ; \theta\right)-v_{R}^{i}\right|^{2}, \\
\operatorname{Loss}_{\hat{v}_{I}}=\frac{1}{N_{I B}} \sum_{i=1}^{N_{I B}}\left|\hat{v}_{I}\left(\mathbf{x}_{I B}^{i}, t_{I B}^{i} ; \theta\right)-v_{I}^{i}\right|^{2}, \\
\operatorname{Loss}_{f_{A}}=\frac{1}{N_{f}} \sum_{j=1}^{N_{f}}\left|f_{\hat{u}}\left(\mathbf{x}_{f}^{j}, t_{f}^{j}\right)\right|^{2}, \\
\operatorname{Loss}_{f_{B}}=\frac{1}{N_{f}} \sum_{j=1}^{N_{f}}\left|f_{\hat{v}}\left(\mathbf{x}_{f}^{j}, t_{f}^{j}\right)\right|^{2}, \\
\operatorname{Loss}_{f_{R}}=\frac{1}{N_{f}} \sum_{j=1}^{N_{f}}\left|f_{R}\left(\mathbf{x}_{f}^{j}, t_{f}^{j}\right)\right|^{2}, \\
\operatorname{Loss}_{f_{I}}=\frac{1}{N_{f}} \sum_{j=1}^{N_{f}}\left|f_{I}\left(\mathbf{x}_{f}^{j}, t_{f}^{j}\right)\right|^{2}, \tag{2.8}
\end{array}\right. ⎩ ⎨ ⎧ Loss u ^ R = N I B 1 ∑ i = 1 N I B u ^ R ( x I B i , t I B i ; θ ) − u R i 2 , Loss u ^ I = N I B 1 ∑ i = 1 N I B u ^ I ( x I B i , t I B i ; θ ) − u I i 2 , Loss v ^ R = N I B 1 ∑ i = 1 N I B v ^ R ( x I B i , t I B i ; θ ) − v R i 2 , Loss v ^ I = N I B 1 ∑ i = 1 N I B v ^ I ( x I B i , t I B i ; θ ) − v I i 2 , Loss f A = N f 1 ∑ j = 1 N f f u ^ ( x f j , t f j ) 2 , Loss f B = N f 1 ∑ j = 1 N f f v ^ ( x f j , t f j ) 2 , Loss f R = N f 1 ∑ j = 1 N f f R ( x f j , t f j ) 2 , Loss f I = N f 1 ∑ j = 1 N f f I ( x f j , t f j ) 2 , ( 2.8 ) 其中,{ x I B i , t I B i , u R i , u I i , v R i , v I i } i = 1 N I B \{x^i_{IB},t^i_{IB}, u^i_R,u^i_I,v^i_R,v^i_I\}^{N_{IB}}_{i=1} { x I B i , t I B i , u R i , u I i , v R i , v I i } i = 1 N I B { x f j , t f j } j = 1 N f \{x^j_f, t^j_f \}^{N_f}_{j=1} { x f j , t f j } j = 1 N f f A , f B , f R , f I f_A,f_B,f_R,f_I f A , f B , f R , f I
相反,PINN 也证明了解决与非局部可积偏微分方程相关的逆问题的有效性,即未确定参数和数值解同时学习。在方程(2.1)中存在未知参数的情况下,这些参数可以通过在标记训练点 { x l i , t l i , u R i , u I i , v R i , v I i } i = 1 N l \{x^i_{l},t^i_{l}, u^i_R,u^i_I,v^i_R,v^i_I\}^{N_{l}}_{i=1} { x l i , t l i , u R i , u I i , v R i , v I i } i = 1 N l \(\hat{u}_R(\mathbf{x},t;θ),\hat{u}_I(\mathbf{x},t;θ),\hat{v}_R(\mathbf{x},t;θ),\hat{v}_I(\mathbf{x},t;θ)\) 来获得。这涉及引入额外的数据丢失项
L o s s l = 1 N l ∑ i = 1 N l [ ∣ u ^ R ( x l i , t l i ; θ ) − u R i ∣ 2 + ∣ u ^ I ( x l i , t l i ; θ ) − u I i ∣ 2 + ∣ v ^ R ( x l i , t l i ; θ ) − v R i ∣ 2 + ∣ v ^ I ( x l i , t l i ; θ ) − v I i ∣ 2 ] , (2.9) \begin{aligned}
Loss_l=\frac{1}{N_l}\sum_{i=1}^{N_l}{\left[|\hat{u}_R(\mathbf{x}_{l}^{i},t_{l}^{i};\theta )-u_{R}^{i}|^2+|\hat{u}_I(\mathbf{x}_{l}^{i},t_{l}^{i};\theta )-u_{I}^{i}|^2 \right.}\\
\left. +|\hat{v}_R(\mathbf{x}_{l}^{i},t_{l}^{i};\theta )-v_{R}^{i}|^2+|\hat{v}_I(\mathbf{x}_{l}^{i},t_{l}^{i};\theta )-v_{I}^{i}|^2 \right] ,\\ \tag{2.9}
\end{aligned} L os s l = N l 1 i = 1 ∑ N l [ ∣ u ^ R ( x l i , t l i ; θ ) − u R i ∣ 2 + ∣ u ^ I ( x l i , t l i ; θ ) − u I i ∣ 2 + ∣ v ^ R ( x l i , t l i ; θ ) − v R i ∣ 2 + ∣ v ^ I ( x l i , t l i ; θ ) − v I i ∣ 2 ] , ( 2.9 ) 因此,偏微分方程的逆问题的损失函数为
L o s s θ = L o s s l + L o s s u ^ R + L o s s u ^ I + L o s s v ^ R + L o s s v ^ I + L o s s f A + L o s s f B + L o s s f R + L o s s f I . (2.10) \begin{aligned}
Loss_{\theta}=Loss_l+Loss_{\hat{u}_R}+Loss_{\hat{u}_I}+Loss_{\hat{v}_R}+Loss_{\hat{v}_I}\\
+Loss_{f_A}+Loss_{f_B}+Loss_{f_R}+Loss_{f_I}.\\ \tag{2.10}
\end{aligned} L os s θ = L os s l + L os s u ^ R + L os s u ^ I + L os s v ^ R + L os s v ^ I + L os s f A + L os s f B + L os s f R + L os s f I . ( 2.10 ) 为方便起见,I B IB I B
L o s s θ = L o s s l + L o s s f A + L o s s f B + L o s s f R + L o s s f I . (2.11) Loss_{\theta}=Loss_l+Loss_{f_A}+Loss_{f_B}+Loss_{f_R}+Loss_{f_I}. \tag{2.11} L os s θ = L os s l + L os s f A + L os s f B + L os s f R + L os s f I . ( 2.11 ) 与原始 PINN 不同,PTS-PINN 的优化目标是最小化损失函数,该函数现在除了 PINN 损失函数外,还包括 PT -对称残差。这一优化过程包括更新权重和偏差。为了全面概述 PTS-PINN 方法论,我们在图 1 中展示了示意图。
前向问题的数值实验
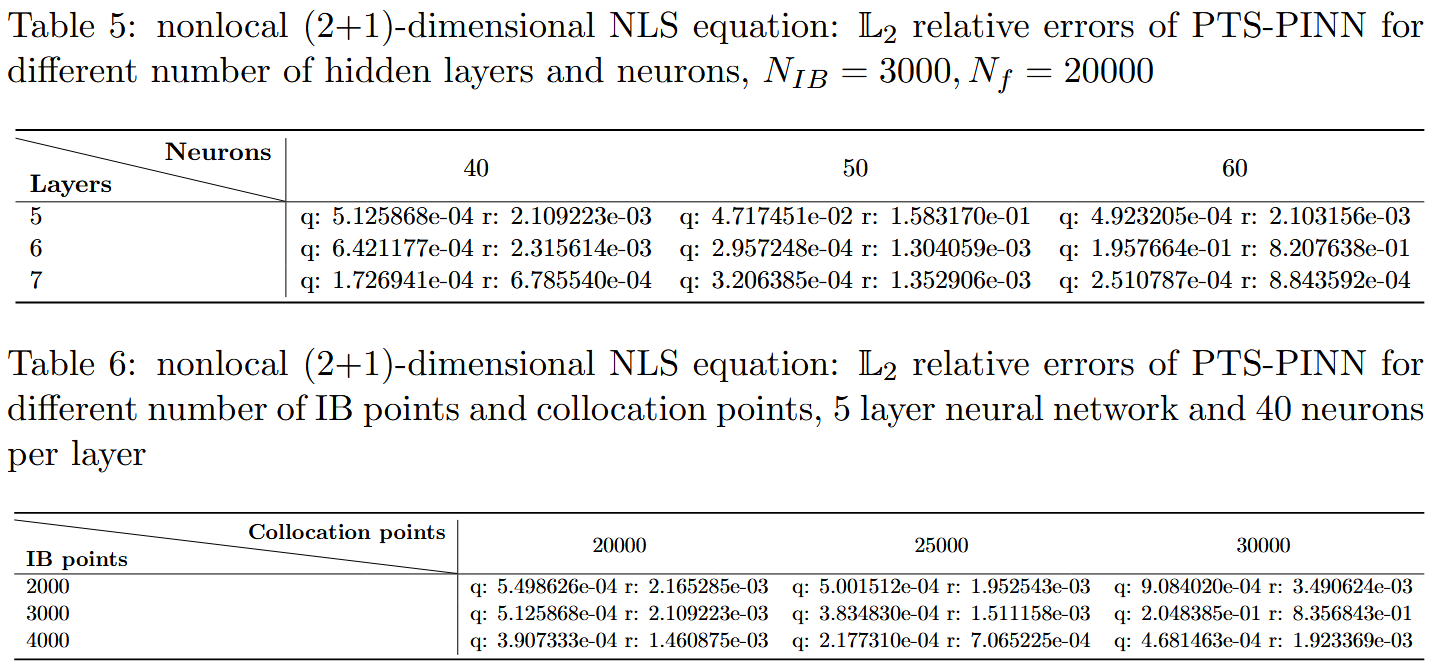
本节主要考虑若干类非局部方程的正问题,包括非局部 NLS 方程、非局部导数 NLS 方程和非局部(2+1)维 NLS 方程。这里,我们使用 Tensorflow 实现神经网络,所有数值实验均在配备 2.10 GHz 8 核 Xeon Silver 4110 处理器和 64GB 内存的 DELL Precision 7920 塔式计算机上运行。估计的准确性通过相对 L2 误差来评估,这一指标是衡量算法有效性的可靠指标。精确值 q ( x k , t k ) q(\mathbf{x}_k,t_k) q ( x k , t k ) q ^ ( x k , t k ) \hat{q}(\mathbf{x}_k,t_k) q ^ ( x k , t k ) x k , t k k = 1 N {\mathbf{x}_k, t_k}^N_{k=1} x k , t k k = 1 N
E r r o r = ∑ k = 1 N ∣ q ( x k , t k ) − q ^ ( x k , t k ) ∣ 2 ∑ k = 1 N ∣ q ( x k , t k ) ∣ 2 . (3.1) \mathrm{Error}=\frac{\sqrt{\sum_{k=1}^N{\left| q(\mathbf{x}_k,t_k)-\hat{q}(\mathbf{x}_k,t_k) \right|^2}}}{\sqrt{\sum_{k=1}^N{\left| q(\mathbf{x}_k,t_k) \right|^2}}}. \tag{3.1} Error = ∑ k = 1 N ∣ q ( x k , t k ) ∣ 2 ∑ k = 1 N ∣ q ( x k , t k ) − q ^ ( x k , t k ) ∣ 2 . ( 3.1 ) 非局部 NLS 方程
非局部 NLS 方程及狄利克雷边界条件为[59]
{ i q t ( x , t ) + q x x ( x , t ) + 1 2 q 2 ( x , t ) q ∗ ( − x , t ) = 0 , x ∈ [ − 5 , 5 ] , t ∈ [ − 5 , 5 ] , q ( x , − 5 ) = e − 5 i 2 ( 1 − 4 ( 1 − 5 i ) x 2 + 26 ) , q ( − 5 , t ) = q ( 5 , t ) = e i t 2 ( 1 − 4 i t + 4 t 2 + 26 ) . (3.2) \left\{ \begin{array}{l}
iq_t(x,t)+q_{xx}(x,t)+\frac{1}{2}q^2(x,t)q^*(-x,t)=0,\qquad x\in [-5,5],\quad t\in [-5,5],\\
\\
q(x,-5)=e^{-\frac{5i}{2}}(1-\frac{4(1-5i)}{x^2+26}),\\ \tag{3.2}
\\
q(-5,t)=q(5,t)=e^{\frac{it}{2}}(1-\frac{4it+4}{t^2+26}).\\
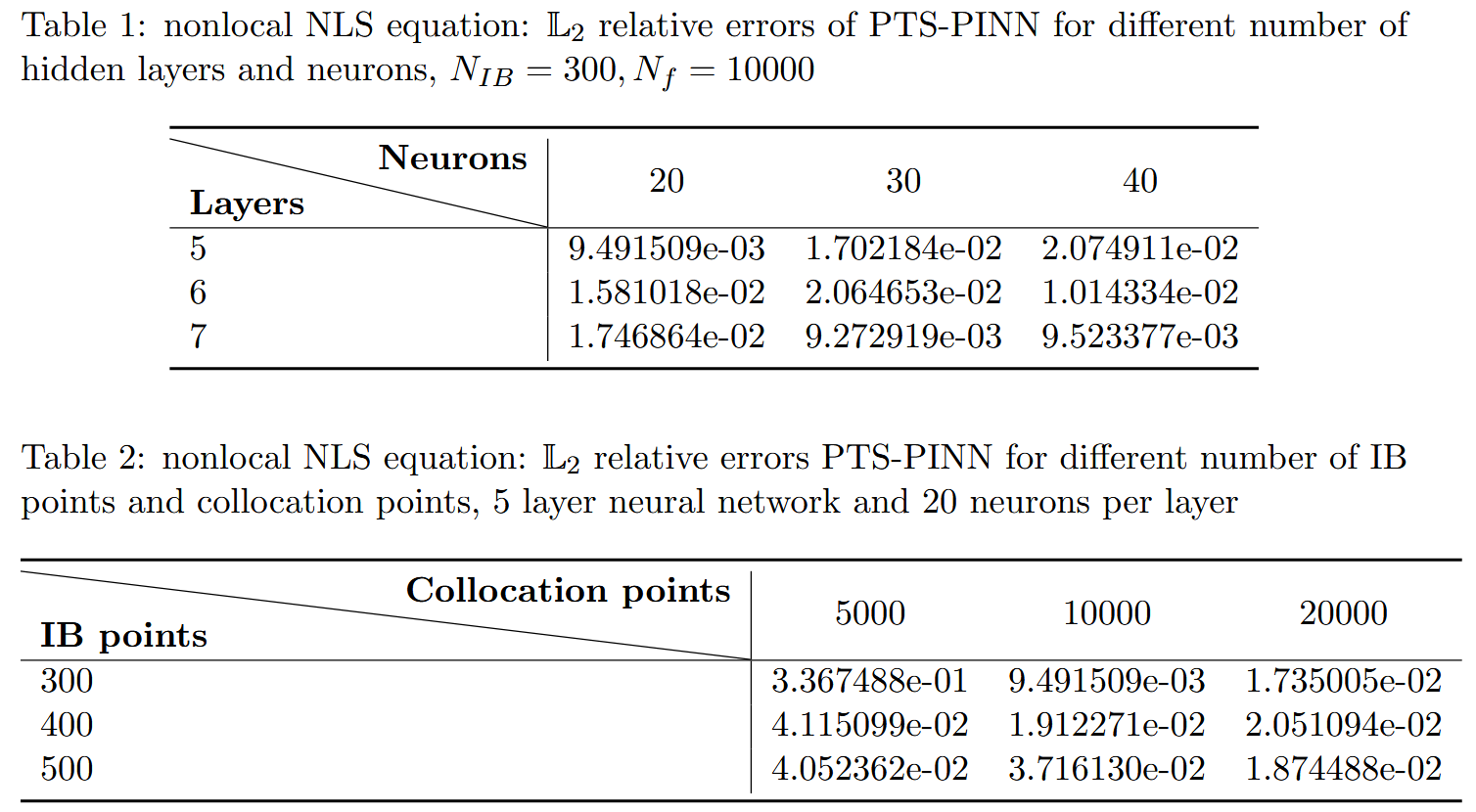
\end{array} \right. ⎩ ⎨ ⎧ i q t ( x , t ) + q xx ( x , t ) + 2 1 q 2 ( x , t ) q ∗ ( − x , t ) = 0 , x ∈ [ − 5 , 5 ] , t ∈ [ − 5 , 5 ] , q ( x , − 5 ) = e − 2 5 i ( 1 − x 2 + 26 4 ( 1 − 5 i ) ) , q ( − 5 , t ) = q ( 5 , t ) = e 2 i t ( 1 − t 2 + 26 4 i t + 4 ) . ( 3.2 ) 本节主要考虑若干类非局部方程的正问题,包括非局部 NLS 方程、非局部导数 NLS 方程和非局部(2+1)维 NLS 方程。这里,我们使用 Tensorflow 实现神经网络,所有数值实验均在配备 2.10 GHz 8 核 Xeon Silver 4110 处理器和 64GB 内存的 DELL Precision 7920 塔式计算机上运行。估计的准确性通过相对 L2 误差来评估,这一指标是衡量算法有效性的可靠指标。精确值 q ( x k , t k ) q(\mathbf{x}_k,t_k) q ( x k , t k ) q ^ ( x k , t k ) \hat{q}(\mathbf{x}_k,t_k) q ^ ( x k , t k ) { x k , t k } k N = 1 \{x_k,t_k\}_k^{N=1} { x k , t k } k N = 1 q ( x , t ) = e i t 2 ( 1 − 4 i t + 4 t 2 + x 2 + 1 ) q(x,t) = e^{\frac{it}{2}}(1 − \frac{4it+4}{t^2+x^2+1}) q ( x , t ) = e 2 i t ( 1 − t 2 + x 2 + 1 4 i t + 4 ) q ( X , T ) q(\mathbf{X},T) q ( X , T ) [ − 5 , 5 ] [−5,5] [ − 5 , 5 ] [ − 5 , 5 ] [−5,5] [ − 5 , 5 ] N I B = 300 N_{IB} = 300 N I B = 300 q ( x , t ) q(\mathbf{x},t) q ( x , t )
非局部导数 NLS 方程
带有狄利克雷边界条件的非局部导数 NLS 方程[27]
{ i q t ( x , t ) − q x x ( x , t ) − ( q 2 ( x , t ) q ∗ ( − x , t ) ) x = 0 , x ∈ [ − 5 , 5 ] , t ∈ [ 0 , 1 ] , q ( x , 0 ) = ( 8 − 8 i ) ( i e − 3 i x − 16 e − i x ) ( i e − 2 i x + 16 ) 2 , q ( − 5 , t ) = ( 8 − 8 i ) ( i e i ( t + 15 ) − 16 e i ( t + 5 ) ) ( i e 10 i + 16 ) 2 , q ( 5 , t ) = ( 8 − 8 i ) ( i e i ( t − 15 ) − 16 e i ( t − 5 ) ) ( i e − 10 i + 16 ) 2 . (3.3) \left\{ \begin{array}{l}
iq_t(x,t)-q_{xx}(x,t)-(q^2(x,t)q^*(-x,t))_x=0,\qquad x\in [-5,5],\quad t\in [0,1],\\
q(x,0)=\frac{(8-8i)(ie^{-3ix}-16e^{-ix})}{(ie^{-2ix}+16)^2},\\ \tag{3.3}
q(-5,t)=\frac{(8-8i)(ie^{i(t+15)}-16e^{i(t+5)})}{(ie^{10i}+16)^2}, q(5,t)=\frac{(8-8i)(ie^{i(t-15)}-16e^{i(t-5)})}{(ie^{-10i}+16)^2}.\\
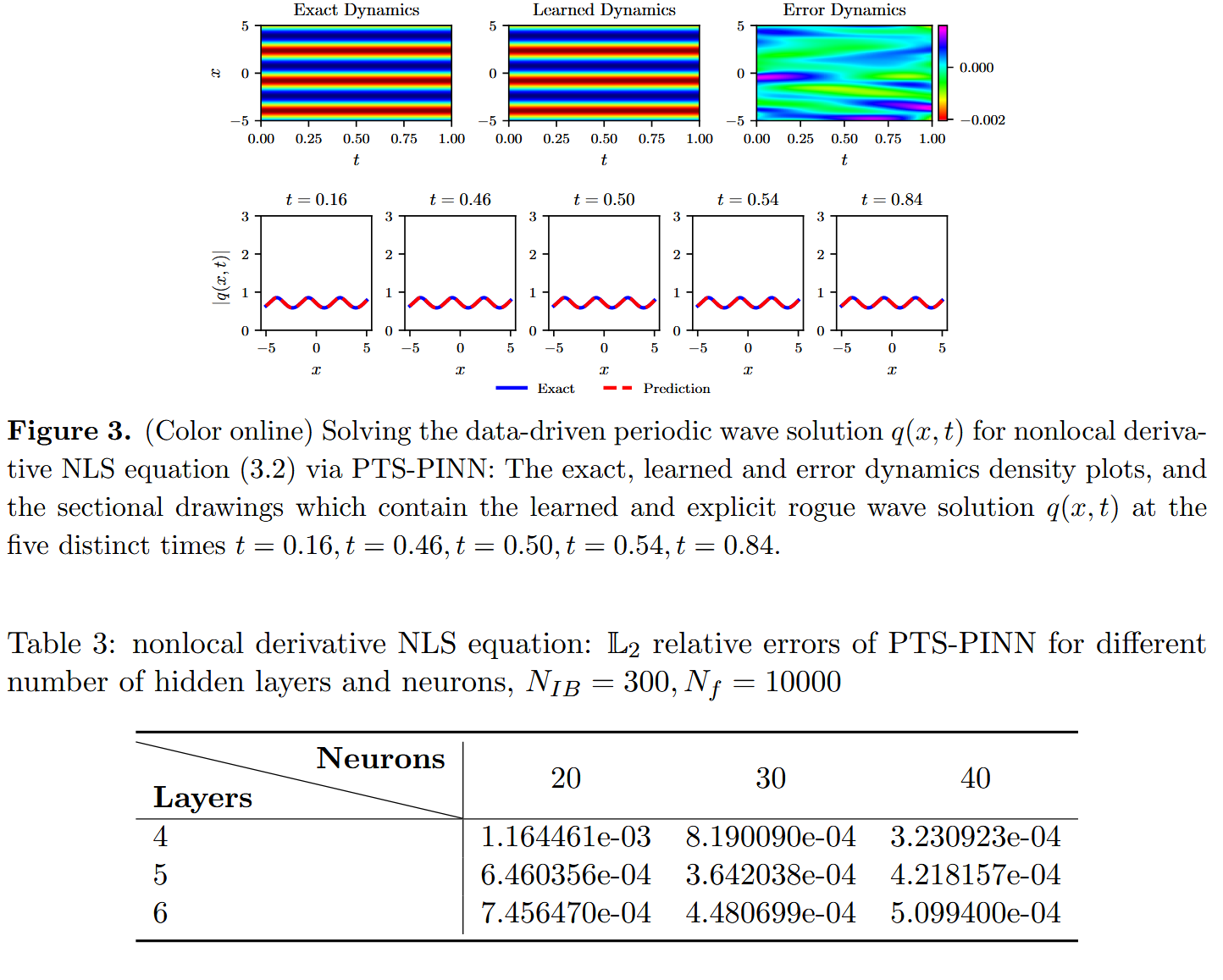
\end{array} \right. ⎩ ⎨ ⎧ i q t ( x , t ) − q xx ( x , t ) − ( q 2 ( x , t ) q ∗ ( − x , t ) ) x = 0 , x ∈ [ − 5 , 5 ] , t ∈ [ 0 , 1 ] , q ( x , 0 ) = ( i e − 2 i x + 16 ) 2 ( 8 − 8 i ) ( i e − 3 i x − 16 e − i x ) , q ( − 5 , t ) = ( i e 10 i + 16 ) 2 ( 8 − 8 i ) ( i e i ( t + 15 ) − 16 e i ( t + 5 ) ) , q ( 5 , t ) = ( i e − 10 i + 16 ) 2 ( 8 − 8 i ) ( i e i ( t − 15 ) − 16 e i ( t − 5 ) ) . ( 3.3 ) 非局部导数 NLS 方程(3.3)的解析解为 q ( x , t ) = ( 8 − 8 i ) ( i e i ( t − 3 x ) − 16 e i ( t − x ) ) ( i e − 2 i x + 16 ) 2 q(x,t) = \frac{(8−8i)(ie^{i(t−3x)}−16e^{i(t−x)})}{(ie^{−2ix}+16)^2} q ( x , t ) = ( i e − 2 i x + 16 ) 2 ( 8 − 8 i ) ( i e i ( t − 3 x ) − 16 e i ( t − x ) ) q ( x , t ) q(x,t) q ( x , t ) [ − 5 , 5 ] [−5,5] [ − 5 , 5 ] [ 0 , 1 ] [0,1] [ 0 , 1 ] N I B = 300 N_{IB} = 300 N I B = 300 N f = 10000 N_f = 10000 N f = 10000 q ( x , t ) q(x,t) q ( x , t )
非局部(2+1)维 NLS 方程
非局部(2+1)维 NLS 方程如下
i q t + q x y + q r = 0 , x ∈ [ − 12 , 12 ] , y ∈ [ − 8 , 8 ] , t ∈ [ − 4 , 4 ] , r y = [ q ( x , y , t ) q ( − x , − y , t ) ∗ ] x , (3.4) \begin{aligned}
iq_t+q_{xy}+qr&=0,\quad x\in [-12,12], y\in [-8,8], t\in [-4,4],\\
r_y&=[q(x,y,t)q(-x,-y,t)^*]_x,\\ \tag{3.4}
\end{aligned} i q t + q x y + q r r y = 0 , x ∈ [ − 12 , 12 ] , y ∈ [ − 8 , 8 ] , t ∈ [ − 4 , 4 ] , = [ q ( x , y , t ) q ( − x , − y , t ) ∗ ] x , ( 3.4 ) 解析解为[28]
q ( x , y , t ) = 1 + i e i x + i y − t + i e − i x − i y − t − 2 e − 2 t 1 + e i x + i y − t + e − i x − i y − t + 2 e − 2 t , r ( x , y , t ) = − 2 e − t ( 2 e − 2 t + i x + i y + 2 e − 2 t − i x − i y + e i ( x + y ) + e − i ( x + y ) + 4 e − t ) ( 1 + e i x + i y − t + e − i x − i y − t + 2 e − 2 t ) 2 , (3.5) \begin{aligned}
q(x,y,t)&=\frac{1+ie^{ix+iy-t}+ie^{-ix-iy-t}-2e^{-2t}}{1+e^{ix+iy-t}+e^{-ix-iy-t}+2e^{-2t}},\\
r(x,y,t)&=-\frac{2e^{-t}(2e^{-2t+ix+iy}+2e^{-2t-ix-iy}+e^{i(x+y)}+e^{-i(x+y)}+4e^{-t})}{(1+e^{ix+iy-t}+e^{-ix-iy-t}+2e^{-2t})^2},\\ \tag{3.5}
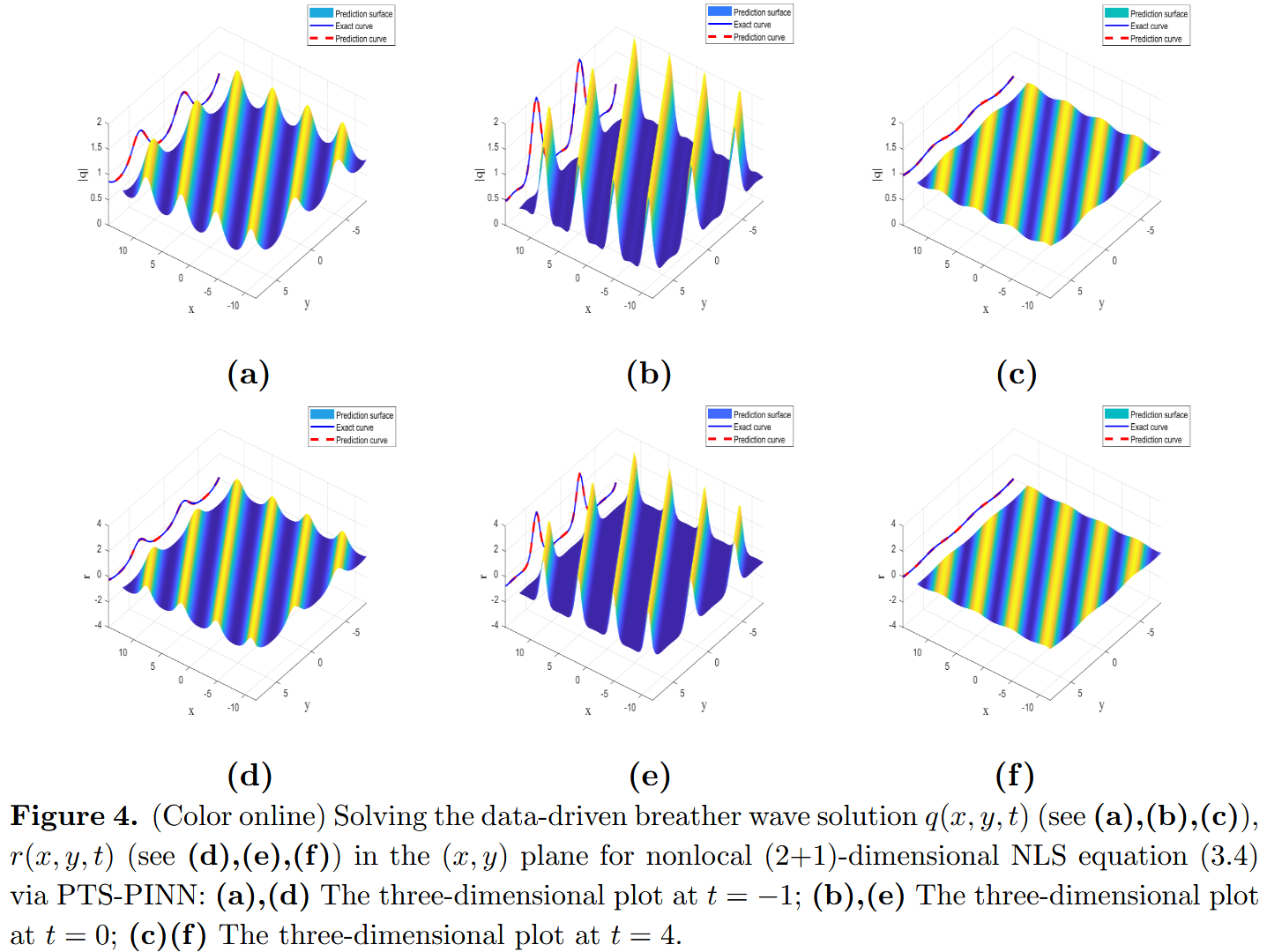
\end{aligned} q ( x , y , t ) r ( x , y , t ) = 1 + e i x + i y − t + e − i x − i y − t + 2 e − 2 t 1 + i e i x + i y − t + i e − i x − i y − t − 2 e − 2 t , = − ( 1 + e i x + i y − t + e − i x − i y − t + 2 e − 2 t ) 2 2 e − t ( 2 e − 2 t + i x + i y + 2 e − 2 t − i x − i y + e i ( x + y ) + e − i ( x + y ) + 4 e − t ) , ( 3.5 ) 这就是呼吸波解。需要强调的是,r ( x , y , t ) r(x,y,t) r ( x , y , t )
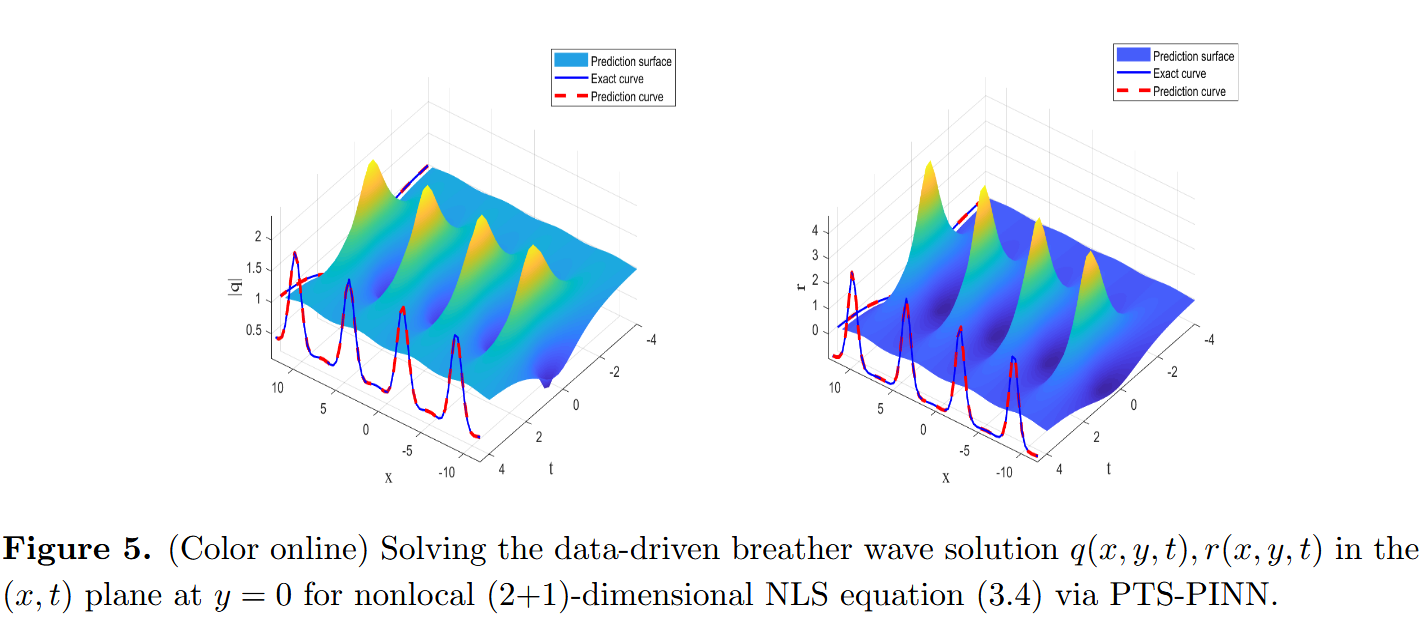
L o s s r = 1 N I B ∑ i = 1 N I B ∣ r ^ ( x I B i , y I B i , t I B i ; θ ) − r i ∣ 2 . (3.6) Loss_r=\frac{1}{N_{IB}}\sum_{i=1}^{N_{IB}}{|\hat{r}(x_{IB}^{i},y_{IB}^{i},t_{IB}^{i};\theta )}-r^i|^2. \tag{3.6} L os s r = N I B 1 i = 1 ∑ N I B ∣ r ^ ( x I B i , y I B i , t I B i ; θ ) − r i ∣ 2 . ( 3.6 ) 我们尝试通过 PTS-PINN 技术获取 q ( x , y , t ) q(x,y,t) q ( x , y , t ) r ( x , y , t ) r(x,y,t) r ( x , y , t ) [ − 12 , 12 ] [−12,12] [ − 12 , 12 ] [ − 8 , 8 ] [−8,8] [ − 8 , 8 ] [ − 4 , 4 ] [−4,4] [ − 4 , 4 ] N I B = 3000 N_{IB} = 3000 N I B = 3000 N f = 20000 N_f = 20000 N f = 20000 q ( x , y , t ) , r ( x , y , t ) q(x,y,t),r(x,y,t) q ( x , y , t ) , r ( x , y , t )
通过 PTS-PINN 解决非局部方程的逆问题
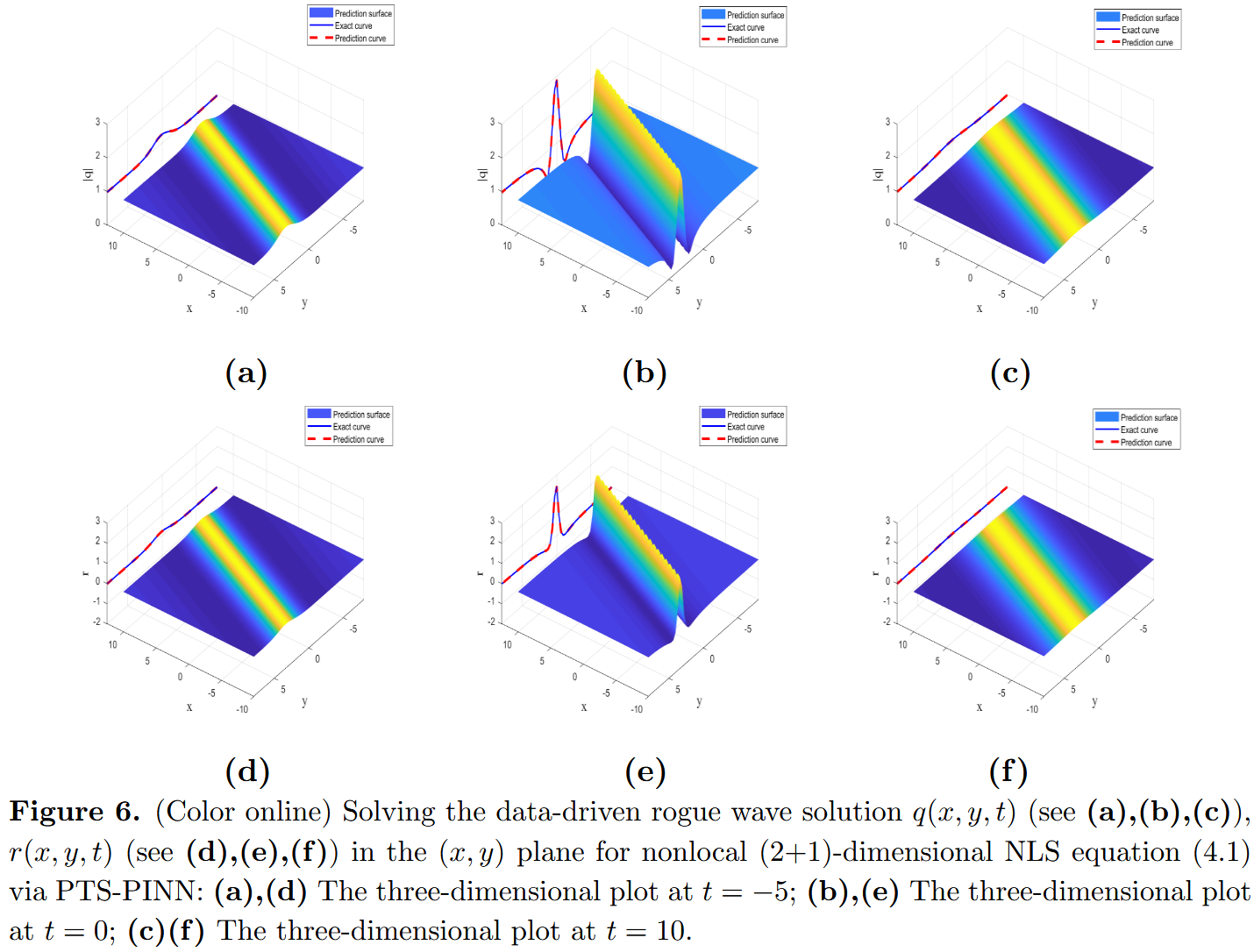
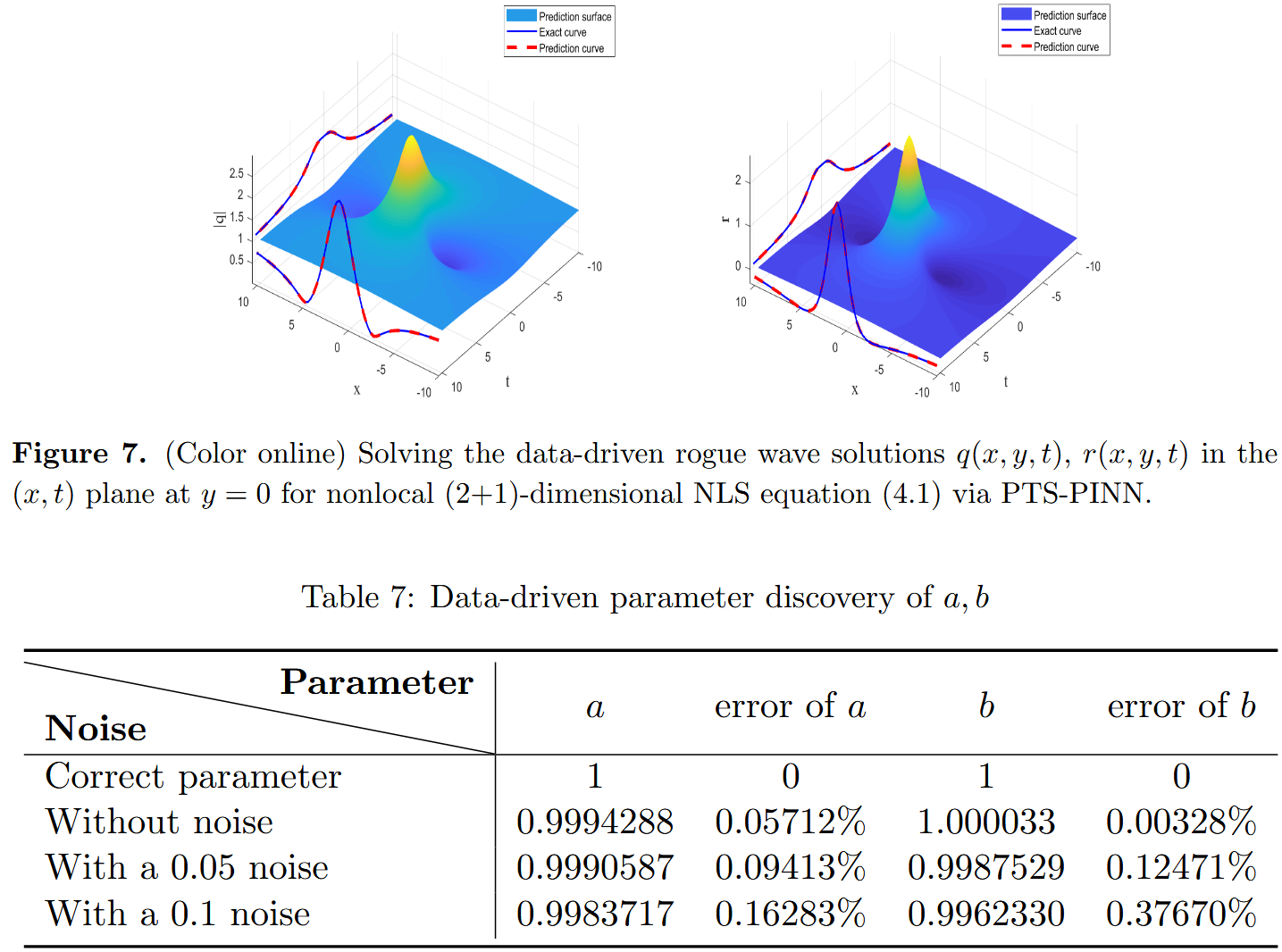
本节重点研究利用 PTS-PINN 方法研究非局部方程相关的逆问题。具体来说,我们深入探讨了非局部(2+1)维 NLS 方程和非局部三波相互作用系统。非局部(2+1)维 NLS 方程以参数形式考虑
i q t + a q x y + q r = 0 , x ∈ [ − 10 , 10 ] , y ∈ [ − 10 , 10 ] , t ∈ [ − 10 , 10 ] , r y = b [ q ( x , y , t ) q ( − x , − y , t ) ∗ ] x . (4.1) \begin{aligned}
iq_t+aq_{xy}+qr&=0,\quad x\in [-10,10], y\in [-10,10], t\in [-10,10],\\
r_y&=b[q(x,y,t)q(-x,-y,t)^*]_x.\\ \tag{4.1}
\end{aligned} i q t + a q x y + q r r y = 0 , x ∈ [ − 10 , 10 ] , y ∈ [ − 10 , 10 ] , t ∈ [ − 10 , 10 ] , = b [ q ( x , y , t ) q ( − x , − y , t ) ∗ ] x . ( 4.1 ) 举例来说,我们设 a = 1 a = 1 a = 1 b = 1 b = 1 b = 1
q ( x , y , t ) = 1 − 12 i t + 18 ( x + 3 y ) 2 + 2 t 2 + 4.5 , r ( x , y , t ) = − 12 ( x + 3 y ) 2 + 24 t 2 + 54 ( ( x + 3 y ) 2 + 2 t 2 + 4.5 ) 2 . (4.2) q(x,y,t)=1-\frac{12it+18}{(x+3y)^2+2t^2+4.5},\quad r(x,y,t)=\frac{-12(x+3y)^2+24t^2+54}{((x+3y)^2+2t^2+4.5)^2}. \tag{4.2} q ( x , y , t ) = 1 − ( x + 3 y ) 2 + 2 t 2 + 4.5 12 i t + 18 , r ( x , y , t ) = (( x + 3 y ) 2 + 2 t 2 + 4.5 ) 2 − 12 ( x + 3 y ) 2 + 24 t 2 + 54 . ( 4.2 ) 非局部三波相互作用系统,以参数形式表示为:
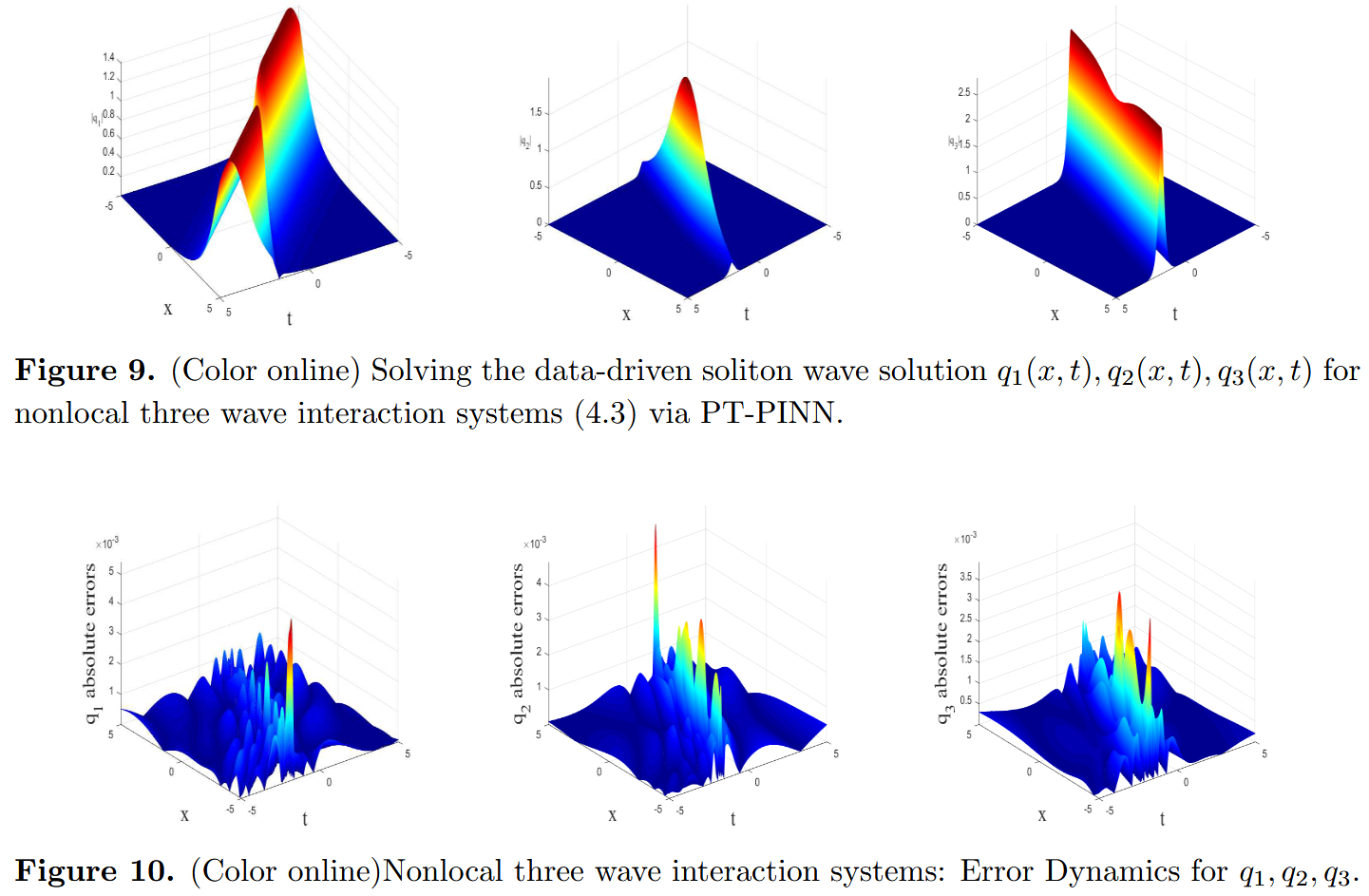
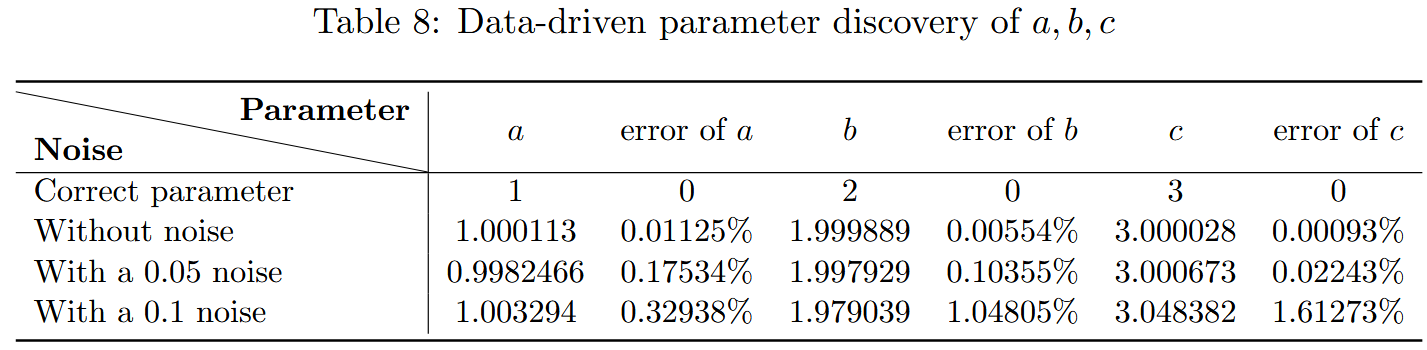
q 1 t + a q 1 x − q 2 ( − x , − t ) q 3 ( − x , − t ) = 0 , q 2 t + b q 2 x − q 1 ( − x , − t ) q 3 ( − x , − t ) = 0 , q 3 t + c q 3 x + q 1 ( − x , − t ) q 2 ( − x , − t ) = 0 , (4.3) \begin{aligned}
q_{1t}+aq_{1x}-q_2(-x,-t)q_3(-x,-t)&=0,\\
q_{2t}+bq_{2x}-q_1(-x,-t)q_3(-x,-t)&=0,\\ \tag{4.3}
q_{3t}+cq_{3x}+q_1(-x,-t)q_2(-x,-t)&=0,\\
\end{aligned} q 1 t + a q 1 x − q 2 ( − x , − t ) q 3 ( − x , − t ) q 2 t + b q 2 x − q 1 ( − x , − t ) q 3 ( − x , − t ) q 3 t + c q 3 x + q 1 ( − x , − t ) q 2 ( − x , − t ) = 0 , = 0 , = 0 , ( 4.3 ) 其中,x ∈ [ − 5 , 5 ] , t ∈ [ − 5 , 5 ] x \in [−5,5],t \in [−5,5] x ∈ [ − 5 , 5 ] , t ∈ [ − 5 , 5 ]
q 1 ( x , t ) = − 2 6 e t − x ( − 1 + e 12 t − 4 x ) 3 e 14 t − 6 x + e 12 t − 4 x + e 2 t − 2 x + 3 , q 2 ( x , t ) = − 16 e 7 t − 3 x 3 e 14 t − 6 x + e 12 t − 4 x + e 2 t − 2 x + 3 , q 3 ( x , t ) = 4 6 e − 6 t + 2 x ( 1 + e − 2 t + 2 x ) 3 e − 14 t + 6 x + e − 12 t + 4 x + e − 2 t + 2 x + 3 . (4.4) \begin{aligned}
q_1(x,t)&=-\frac{2\sqrt{6}e^{t-x}(-1+e^{12t-4x})}{3e^{14t-6x}+e^{12t-4x}+e^{2t-2x}+3},\\
q_2(x,t)&=-\frac{16e^{7t-3x}}{3e^{14t-6x}+e^{12t-4x}+e^{2t-2x}+3},\\ \tag{4.4}
q_3(x,t)&=\frac{4\sqrt{6}e^{-6t+2x}(1+e^{-2t+2x})}{3e^{-14t+6x}+e^{-12t+4x}+e^{-2t+2x}+3}.\\
\end{aligned} q 1 ( x , t ) q 2 ( x , t ) q 3 ( x , t ) = − 3 e 14 t − 6 x + e 12 t − 4 x + e 2 t − 2 x + 3 2 6 e t − x ( − 1 + e 12 t − 4 x ) , = − 3 e 14 t − 6 x + e 12 t − 4 x + e 2 t − 2 x + 3 16 e 7 t − 3 x , = 3 e − 14 t + 6 x + e − 12 t + 4 x + e − 2 t + 2 x + 3 4 6 e − 6 t + 2 x ( 1 + e − 2 t + 2 x ) . ( 4.4 ) 非局部(2+1)维 NLS 的数值实验
通过采用拉丁超立方体抽样,我们可以随机选择 N l = 5000 N_l = 5000 N l = 5000 N f = 5000 N_f = 5000 N f = 5000 ( x , y , t ) (x,y,t) ( x , y , t ) [ − 10 , 10 ] × [ − 10 , 10 ] × [ − 10 , 10 ] [−10,10]×[−10,10]×[−10,10] [ − 10 , 10 ] × [ − 10 , 10 ] × [ − 10 , 10 ] q ( x , y , t ) , r ( x , y , t ) q(x,y,t),r(x,y,t) q ( x , y , t ) , r ( x , y , t ) q ( x , y , t ) , r ( x , y , t ) q(x,y,t),r(x,y,t) q ( x , y , t ) , r ( x , y , t ) ( x , y ) (x,y) ( x , y ) ( x , t ) (x,t) ( x , t )
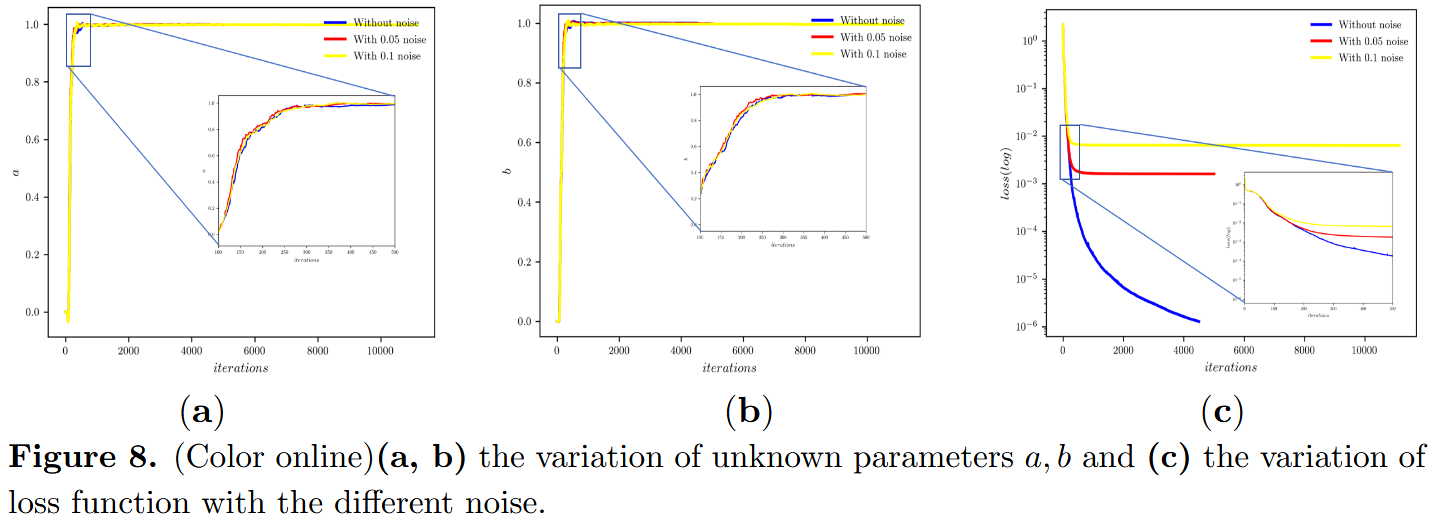
在逆问题的背景下,我们仔细观察未知参数和损耗函数在不同噪声水平下迭代次数的变化。图 8(a)和(b)展示了在不同�噪声条件下迭代时未知参数的变化。值得注意的是,我们观察到即使在噪声存在的情况下,PTS-PINN 在大约 300 次迭代后仍能有效学习未知参数。图 8(c)显示了随着迭代次数增加,在不同噪声水平下损失函数的波动。研究结果表明,随着噪声水平的升高,收敛效应逐渐减弱。这强调了噪声对学习过程收敛行为的影响。
非局部三波相互作用系统的数值实验
随机选择 N l = 1000 N_l = 1000 N l = 1000 N f = 1000 N_f = 1000 N f = 1000 q 1 ( x , t ) , q 2 ( x , t ) , q 3 ( x , t ) q_1(x,t),q_2(x,t),q_3(x,t) q 1 ( x , t ) , q 2 ( x , t ) , q 3 ( x , t ) a , b , c a,b,c a , b , c q 1 ( x , t ) , q 2 ( x , t ) , q 3 ( x , t ) q_1(x,t),q_2(x,t),q_3(x,t) q 1 ( x , t ) , q 2 ( x , t ) , q 3 ( x , t )
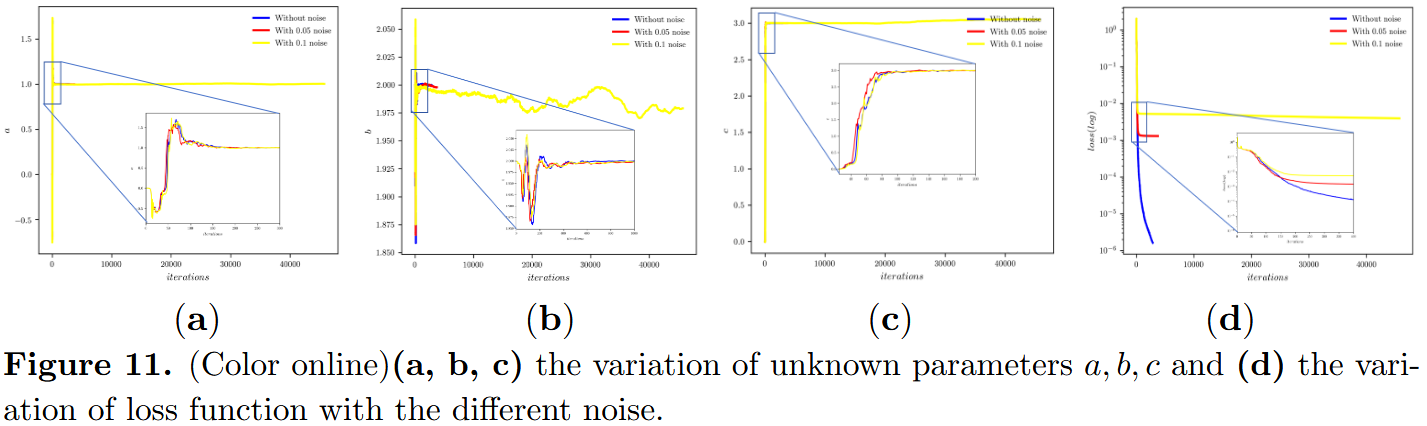
图 11(a)、(b)和(c)分析了在不同噪声水平下,未知参数和损耗函数随迭代次数的变�化。从这些图中,我们观察到参数 a 大约需要 200 次迭代后学习,而参数 b 大约需要 600 次迭代,参数 c 大约需要 100 次迭代。与图 8 类似,对于非定域三波相互作用系统,PTS-PINN 即使在存在噪声的情况下也能很好地找到参数。然而,噪声也会对损失函数的收敛效应产生负面影响。
本文旨在通过将非局部方程的 PT -对称性质纳入 PINN 损耗函数,提升 PINN 算法在求解可积非局域模型中的有效性。通过系统研究 PTS-PINN 在不同 IB 点、搭配点、隐藏层和每层神经元数变化下的表现,我们验证了 PTS-PINN 算法的高效性。特别强调 PTS-PINN 算法在学习与非局域方程相关的流氓波方面的卓越能力,即使在大时空尺度上也是如此。此外,我们研究了 PTS-PINN 在求解非局域导数 NLS 方程中的表现。对于学习周期波,PTS-PINN 算法的精度达到 e-04 阶级。我们将挑战扩展到用 PTS-PINN 准确求解非局域(2+1)维 NLS 方程,数据驱动的呼吸波解是完美学习的。本文展示了上述非局域偏微分方程的详细数值实验结果,以展示 PTS-PINN 方法的有效性。此外,我们采用 PTS-PINN 确定非局域(2+1)维 NLS 方程和非局域三波相互作用系统中涉及的参数。实验结果一贯显示 PTS-PINN 算法在解决非局部方程逆问题方面的卓越表现。我们相信,我们的研究成果将有助于理解和解析其他非局域可积系统的研究。
补充材料以及原文链接
📌 欢迎关注 FEMATHS 小组与山海数模,持续学习更多数学建模与科研相关知识!
论文链接在这里:https://www.sciencedirect.com/science/article/pii/S0010465525001742